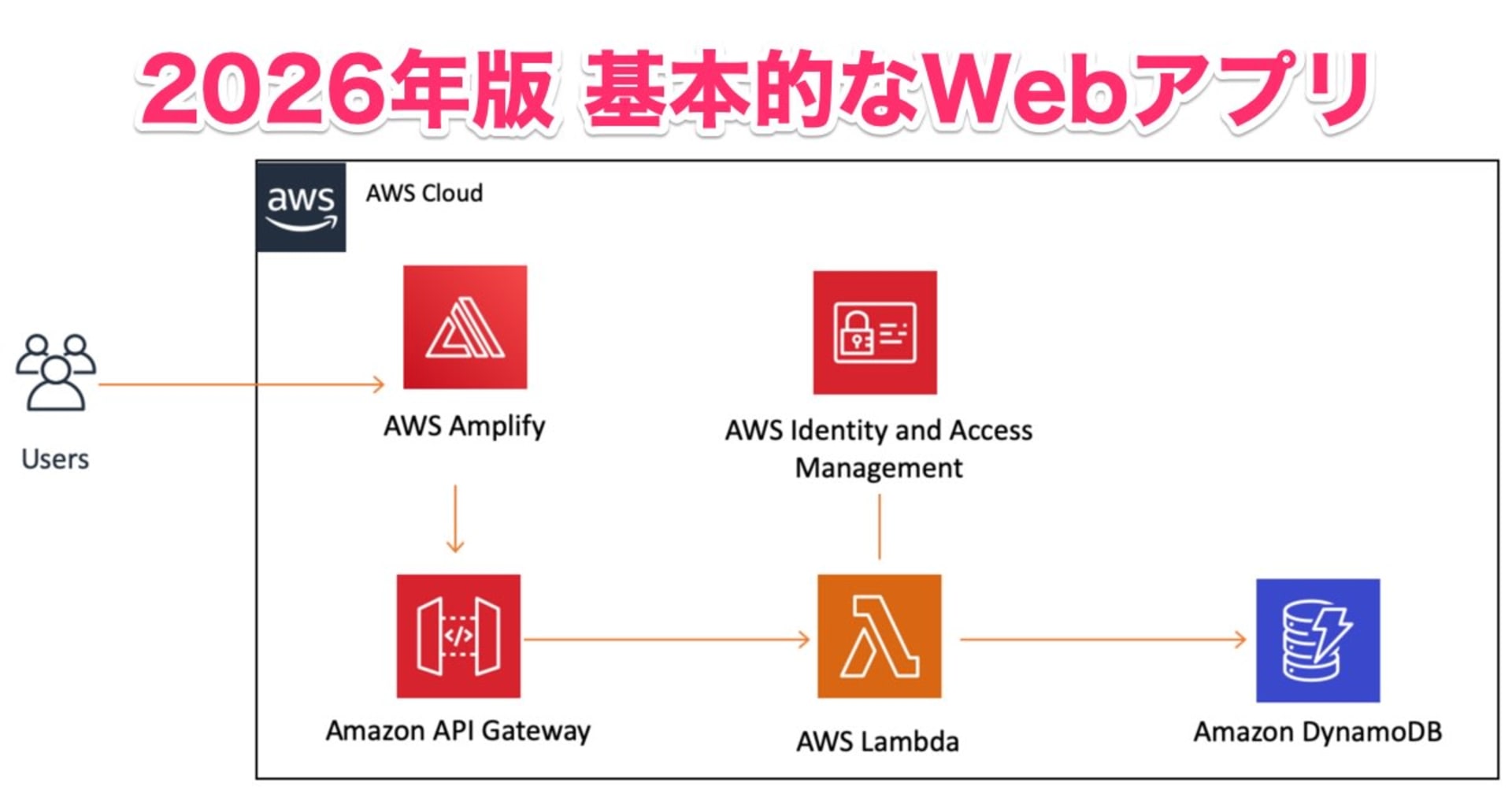
今度こそ理解する!俺式Lambda入門
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
こんにちは、平野です。
AWS Lambdaがやっと使えるようになってきました。 私は新しい物事を理解しようと思った時、 「できるだけ最小限な構成から少しずつ要素を増やしていって、 そこから挙動を類推して確かめる」 というような調べ方でないとどうにも腑に落ちない性格のようなので、 そんな感じでLambdaも試行錯誤してみました。
Lambdaについては前から面白そうだと思いつつもなかなか手を出せずにいました。 事前の知識としては「あるイベントが起きたら、何らかのイベントを起こすもの」 ぐらいのふわっとした理解しかありませんでしたが、 私と同じ辺りの出発点からスタートする人の参考になればと思います。
最小限でLambdaを構成する
ということで、できるだけ最小限の構成でLambdaを動かしてみます。
作るもの
以下のような動作で検証を行います。 究極的に最小限というわけでは無いですが、初心者でもまず分かりやすい構成だと思います。
トリガーイベント: S3へのファイル投入 一番ベタですが、やはり一番わかりやすいです。
実行される処理: 適当な文字列の表示 Lambdaはサーバーレス(どこかの知らないサーバーで動いている)ですが、 CloudWatch Logsというログ監視を通して文字列をみることができます。
作成手順
早速関数を作成していきます。
 「一から作成」していきます。
「一から作成」していきます。
 ロールは新規作成します。
ポリシーテンプレートは「1つ以上」と書かれていますが、特に何も選択しなくても大丈夫です。
ロールは新規作成します。
ポリシーテンプレートは「1つ以上」と書かれていますが、特に何も選択しなくても大丈夫です。
上記のように設定すれば、次のような画面に移ります。
 これがLambda関数のメイン画面(勝手に命名)です。
これがLambda関数のメイン画面(勝手に命名)です。
 左の赤い部分にはトリガーが並びます。
トリガーは複数を並べることができますが、今回は1つしか使いません。
左の赤い部分にはトリガーが並びます。
トリガーは複数を並べることができますが、今回は1つしか使いません。
右の青い部分には、この関数がアクセス権限を持つAWSのサービスが並びます。 はじめ私はこの部分を、「実行される処理の対象サービス」が表示されているものだと思ってしまいました。 左がトリガーなので、右はそれによって実行される処理が並ぶものだと早合点していたのです。 しかし画面にも書いてある通り、ここにはアクセス権のあるサービスが並んでいるだけです。 実行される処理では一切触れていないサービスでも、 関数がアクセス権を持っていればここに表示される ので、 勘違いしないようにしましょう。 なお、関数のアクセス権限とは、とりもなおさずロールのアクセス権限のことです。 今回はポリシーテンプレートを1つも選択せずにロールを新規作成しました。 「CloudWatch Logs」はデフォルトで必ず含まれるようですが、 それ以外にはどのサービスにもアクセスできないロールになっていることがわかります。
本題に戻って、関数作成の続きです。
左のペインからS3をクリックしてトリガーとして追加します。

 「バケット」「プレフィックス」「サフィックス」を設定します。
「バケット」「プレフィックス」「サフィックス」を設定します。
cm-hirano-shigetoshi-testバケットの、targets/*txtのような
オブジェクトが作成された時にのみイベントが起こるようにしました。
また、「トリガーの有効化」にはチェックをつけておきます。
次にコードの編集です。
関数名の部分をクリックすると下部にコード編集画面が出てきます。
 最初のコードはたった2行です。
最初のコードはたった2行です。
def lambda_handler(event, context):
print("Lambdaが呼ばれたよ!!!!!!")
編集が終わったら「保存」ボタンを押して保存しておきます。
 コードの内容は説明するまでもないですが、
「トリガーイベントが起きたら
コードの内容は説明するまでもないですが、
「トリガーイベントが起きたらlambda_handlerが呼ばれ、何かしらprintして終わり」です。
これで最小限の関数が一通り完成です。
「テスト」での確認
次に動作の確認です。
Lambdaにはテスト機能があるので、まずはそれで実行してみます。
 テストイベントの設定
テストイベントの設定
 「イベント名」に適当な名前を入れて、テスト内容のJsonは豪快にカラにしてしまいます。
テストも最小限に、というわけです。
「イベント名」に適当な名前を入れて、テスト内容のJsonは豪快にカラにしてしまいます。
テストも最小限に、というわけです。
test01を作成したら「テスト」を押してテストを実行します。
テストが成功して以下のようなログが見れるはずです。
 一応下の方に「Lambdaが呼ばれたよ!!!!!!」の表示が確認できました。
一応下の方に「Lambdaが呼ばれたよ!!!!!!」の表示が確認できました。
また、ログ画面内のリンクからCloudWatch Logsのログを確認することができます。
こちらにもプリントの内容が表示されています。
なお、この画面は今後の確認のために画面を開いておいてください。

S3に投入してテスト
内部に仕込まれたテストだけでは、実際に挙動が確認できた気がしませんので、
実際にトリガーとなる行為を行うことでコードを実行してみます。
今回はマネジメントコンソールからS3にファイルをアップロードしてみます。
トリガーイベント設定に合致した名前のファイルをアップロードします。
 先ほどのCloudWatch Logsの画面を更新すると、
「Lambdaが呼ばれたよ!!!!!!」の表示が確認できます。
先ほどのCloudWatch Logsの画面を更新すると、
「Lambdaが呼ばれたよ!!!!!!」の表示が確認できます。
 (画像は使い回しですが、S3にファイルが置かれた時刻と連動していることが確認できます)
(画像は使い回しですが、S3にファイルが置かれた時刻と連動していることが確認できます)
これで最小限の関数でLambdaの挙動を確認することができました。
ここまでのまとめ
非常に簡単でしたが、最小限な内容としては以上です。 以下のように、トリガーイベントと実行される処理は、 それぞれ独立しているように分けて考えることが可能です。
トリガーイベントの作成
トリガーイベントはマネジメントコンソール上でいくつかの要素を設定することで作成しました。 後続でどんな処理をさせるかを考える必要はありません。
実行される処理
実行される処理の内容は、全てプログラムのコードとして書きます。 ただ単に動作の内容をプログラムで記述するだけです。 コードにはトリガーに依存した部分はありません。
オブジェクトの情報を使う
先ほどの例では、トリガーは「ただタイミングを伝えるもの」としてしか使われていませんでした。 置いたオブジェクトの名前が何だろうが、中身にどんな情報が入っていようが、 とにかく「置かれた」という事実しか使いませんでした。
もちろんそれらの情報を使ったプログラムを書くことができます。
やり方は簡単で、lambda_handlerに渡された引数eventにはトリガーイベントの情報が含まれているので、
そこから欲しい情報を取り出すだけです。
S3のバケット名とオブジェクトのキー(パス)を取得する場合は以下のようなコードです。
def lambda_handler(event, context):
print("Lambdaが呼ばれたよ!!!!!!")
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = event['Records'][0]['s3']['object']['key']
print("bucket =", input_bucket)
print("key =", input_key)
コードを更新して保存し、再びS3にオブジェクトを置いてみます。
CloudWatch Logsの画面を更新すれば
 バケット名とキーが取得出来ました。
追加されたのがどのオブジェクトなのかわかるようになったので、
そのオブジェクトを対象とした処理を書くことができます。
バケット名とキーが取得出来ました。
追加されたのがどのオブジェクトなのかわかるようになったので、
そのオブジェクトを対象とした処理を書くことができます。
test01を実行した場合
ここで試しに先ほど作成したテスト「test01」を実行してみると、実行が失敗します。
理由は簡単で、test01ではカラのJsonなのでeventの中身もカラになっており、
そこから情報を取り出そうとするとエラーになってしまいます。
試しにJsonにbucketとkeyの情報を渡して実行すれば、問題なく動作します。
ということで、 テストのJsonには、引数として渡すeventを書く のだということがわかりました。
ロール
さて、ここで思い出しておきたいことがあります。 それは、このLambda関数(のロール)はS3へのアクセス権限を持っていないということです。 S3へのアクセス権限は持っていませんがバケット名とキーの情報を取ることができています。 これは、トリガーイベントから通知された情報だからOKと考えれば合点がいきます。 Lambda関数は取りにいったのではなく、教えてもらっただけだと。
そう考えると、 ロールのアクセス権限と、トリガーイベントから送られてくる情報は無関係 であることがわかります。 ロールを設定する際にトリガーイベントのことを考える必要はなく、 実行するコードの中で触りたいサービスだけを考えればOKです。
S3のファイルをコピーする関数を作る
最後に、文字列のprintだけではなく、S3にオブジェクトを出力して見ます。 簡単に、投入されたオブジェクトをコピーして別のキー(パス)に出力してみます。 実行される処理の変更ですので、基本的にはプログラミングだけの問題です。 あとはそれに合わせてロールを設定します。
コードの変更
コードは以下のようになります。
import boto3
s3 = boto3.client('s3')
def read_file(bucket_name, file_key):
response = s3.get_object(Bucket=bucket_name, Key=file_key)
return response[u'Body'].read().decode('utf-8')
def upload_file(bucket_name, file_key, bytes):
out_s3 = boto3.resource('s3')
s3Obj = out_s3.Object(bucket_name, file_key)
res = s3Obj.put(Body = bytes)
return res
def lambda_handler(event, context):
print("Lambdaが呼ばれたよ!!!!!!")
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = event['Records'][0]['s3']['object']['key']
print("bucket =", input_bucket)
print("key =", input_key)
# S3からファイルを読み込み
text = read_file(input_bucket, input_key)
# outputのキーを設定
output_key = "outputs/" + input_key
# ファイルをS3に出力
upload_file(input_bucket, output_key, bytes(text, 'UTF-8'))
S3からファイルを読み込み、それを別名でアップロードしているだけです。
ロールの設定
S3にアクセスするためのロールの設定をします。 今回はS3オブジェクトの中身を読み込み、さらにアップロードも行いますので、 S3への読み書きの権限が必要になります。
IAMから作成したロールの画面へ行き、ポリシーのアタッチを行います。
動作確認なので、安直にAmazonS3FullAccessをアタッチします。


Lambdaの方に戻って、ページをリロードするとアクセス権限のあるリソースにS3が追加されているのがわかります。

確認
変更は以上で完了ですので、S3にオブジェクトを配置すると、
下記のようにoutputs以下にファイルがコピーされることが確認できます。
 対応するCloudWatchのログも確認できます。
対応するCloudWatchのログも確認できます。

まとめ
Lambdaの初歩を理解するために私が行なった手順をまとめてみました。 行った内容としては本当に簡単な例ですが、逆にその分Lambdaというサービスの提供する機能を浮き彫りに出来たかなと思います。
理解するのに特に重要だと私が感じたポイントは以下でした。
- トリガーイベントは実行コードとは独立している
- トリガーイベントの内容をコードに書く必要はない
event引数だけで疎に結合している- トリガーイベントはロールとも無関係
- トリガーされたらプログラムコードが実行される
- 実行されるサービスはGUIでポチポチではなく、プログラムで表現する
- プログラムが動くので、コードに落とし込めればなんでもできる
- サーバーレスなので、データの永続化に気をつける必要がある
Lambdaの扱いやすさは、やはりトリガーイベントと実行コードが疎結合なことかなと思います。 同じコードでトリガーだけを変更しても、eventの中身しか気にしなくてよいのはラクです。
以上、わかってみれば簡単なことですが、最初は何もわからない状態だったので、 やっぱり自分で一つずつ確かめながら触ってみるのは大切だな、と改めて感じました。
誰かの参考になれば幸いです。